SQL 2일차입니다.
대~~충
rowid에 대해 잠깐 배웠고 Order by 정렬, SQL의 함수 중 단일행 함수인 upper, cncat, length와 같은 문자함수와 round, trunc, mod와 같은 숫자 함수, 마지막으로 month_between, next_day와 같은 날짜 함수에 대해 공부했습니다.
저는, 언제나, sql 시작 전에는 텅텅 비어버린 머리에 DB를 넣어줄겸 뭔 데이터가 있나~~ 확인을 합니다.
DESC로 사용할 테이블 구조도 확인하구요. (아.. 근데 저는 desc로 한 번 보고도 눈에 안 들어와서 그냥 한 번 다 보긴합니다. ㅎㅎㅎ)
--SQL_2일차
select * from tab;
desc EMPLOYEES;
select * from employees;
먼저, rowid에 대해서 배웠는데....
음... 딴생각을 좀 했었따.

그래도 적어놓은게 있으니 보고 이해하려고 노력해보겠다. ㅎㅎㅎㅎ
일단 rowid는 실제 저장된 주소값을 말한다.
총 18글자로 구성되어있으며 6, 3, 6, 3으로 나뉘어서 테이블정보, 파일정보, 블럭정보, 행정보를 갖는다.
select employee_id, last_name, rowid
from employees;
King이라는 Last_name을 갖은 값의 실제 주소값은 AAAEAbAAEAAAADNAAA이고 이 값은 AAAEAb이라는 테이블 주소와 AAE라는 파일 주소 AAAADN 블럭 주소 AAA 행 주소를 갖습니다.
그리고 딱 겉으로 보기에도 위의 값들이 같은 테이블에 존재하는건 팩트. 그리고.. rowid로 보면 해당 파일들은 같은 테이블주소와 파일주소, 블럭주소에 있고 행 주소만 좀 다른 것을 볼 수 있다.
| King | AAAEAb AAE AAAADN AAA |
| Kochhar | AAAEAb AAE AAAADN AAB |
| De Haan | AAAEAb AAE AAAADN AAC |
이후에 다시 설명하신다고 했으니 어디에 써먹는지는 그때 알아보자.

1. Order by 정리 문법
기본적으로 SQL의 정렬은 오름차순으로 정렬이된다. = ASC(end), 내림차순 정렬은 DESC(end) 명령어를 사용한다.
< 문법 >
SELECT [DISTINCT] {*, column [Alias], . . .}
FROM 테이블명
[WHERE 조건식]
ORDER BY { column, 표현식} [ASC|DESC];< 실예 >
SELECT employee_id,last_name,job_id,salary
FROM employees
ORDER BY salary;
SELECT employee_id,last_name,job_id,salary
FROM employees
ORDER BY salary DESC;
1) Order by 정리 문법 (alias (별칭, 가명) 사용 가능)
SELECT employee_id,last_name,job_id,salary as "월급"
FROM employees
ORDER BY 월급 DESC;
2) Order by 정리 문법 (select의 지정된 컬럼 순서를 이용)
SELECT employee_id, last_name, job_id, salary as "월급"
FROM employees
ORDER BY 4 DESC; --여기서 4라는 숫자는 select의 컬럼 중 4번째인 salary(월급)
3) Order by 정리 문법 (문자 데이터 정럴 ==> 아스키 코드를 기준으로 정렬)
SELECT employee_id, last_name as 이름, job_id,salary
FROM employees
ORDER BY last_name ASC; --기본SELECT employee_id, last_name as 이름, job_id,salary
FROM employees
ORDER BY 이름 ASC; -- alias 값으로 정렬SELECT employee_id, last_name as 이름, job_id,salary
FROM employees
ORDER BY 2 ASC; -- column 순서로 정렬
4) Order by 정리 문법 ( 날짜 데이터 정렬 )
SELECT employee_id,last_name,salary,hire_date as 입사일
FROM employees
ORDER BY hire_date DESC; --기본SELECT employee_id,last_name,salary,hire_date as 입사일
FROM employees
ORDER BY 입사일 DESC; -- alias 값으로 정렬SELECT employee_id, last_name, salary, hire_date as 입사일
FROM employees
ORDER BY 4 DESC; -- column 순서로 정렬
5) Order by 정리 문법 ( 다중 데이터 정렬 )
< 문법 >
SELECT [DISTINCT] {*, column [Alias], . . .}
FROM 테이블명
[WHERE 조건식]
ORDER BY {column, 표현식}[ASC|DESC], { column, 표현식} [ASC|DESC];< 실예 >
SELECT employee_id, last_name, salary, hire_date
FROM employees
ORDER BY salary DESC, hire_date; -- 월급으로 내림차순 후 동일값은 입사일 기준 오름차순 정렬
SELECT employee_id, last_name, salary, hire_date
FROM employees
ORDER BY hire_date, salary DESC; -- 입사일로 오름차순 정렬 후, 동일값은 월급 기준 내림차순 정렬
-- Order by 정리 문법은 ==> Null 값을 ==> 가장 큰 값으로 규정
<<< SQL 함수 >>>는 1) 단일행 함수 2)그룹 함수로 나뉩니다.
오늘은 단일행 함수 중, 문자 함수와, 숫자(수치) 함수, 날짜 함수를 살펴봤습니다.
2. 문자 함수 (단일행 함수)
1) INITCAP( 컬럼명|표현식) ==> 단어의 첫 문자를 대문자로 바꾸고 나머지 문자는 소문자로 변경
< 문법 >
SELECT INITCAP('ORACLE SQL')
FROM dual; --dummy 테이블, 실행 값 보고 싶을 때 사용< 실예 >
select job_id --원본 값
from employees;
SELECT INITCAP(job_id) -- initcap 함수 반환 값
from employees;
달라진 점이 잘 안 보인다면 두 값을 같이 표현해보자.
--기존 파일과 함수 반환 파일을 같이 보여줌
SELECT job_id, INITCAP(job_id)
FROM employees;
2) UPPER 함수 ==> 모든 글자 대문자로 --> LOWER 함수도 같은 방식
< 문법 >
UPPER( 컬럼명|표현식)< 실예 >
SELECT UPPER('Oracle Sql')
FROM dual;
-- last_name이 'king'인 사원 조회
select first_name, last_name, salary, department_id
from employees
where upper(last_name) = 'KING';
3) CONCAT 함수 ==> 두 개의 문자열을 연결하여 하나로 만듦 == 연결 연산자 ||
< 문법 >
CONCAT( 컬럼명|표현식 , 컬럼명2|표현식2)< 실예 >
SELECT CONCAT('Oracle',' Sql')
FROM dual;
SELECT CONCAT( last_name, salary) "이름 월급"
FROM employees;SELECT last_name || salary as "이름 월급"
from employees;
4) LENGTH 함수 ==> 문자열 길이 반환
< 문법 >
LENGTH( 컬럼명|표현식)< 실예 >
SELECT LENGTH('Oracle')
FROM dual;
SELECT last_name, LENGTH(last_name) as "이름 길이"
FROM employees;
5) INSTR 함수 ==> 문자열에서 특정 문자가 나나타는 위치 반환
< 문법 >
INSTR( 컬럼명|표현식, 검색값, [m ,n] ) ==> m : index 시작점, n: n번째 검색값의 위치 반환< 실예 >
-- MILLER라는 글자에서 L의 위치를 알려달라. index 1부터 시작, 결과 값 0 => 값 없다.
SELECT INSTR('MILLER' , 'L')
FROM dual; --> m : 처음부터, n : 1번째로 L나오는 위치
SELECT INSTR('MILLER' , 'L', 1, 2), INSTR('MILLER' , 'X', 1 , 2 )
FROM dual; --> 1번 index부터 2번째 L 값의 위치
6) SUBSTR 함수 ==> column의 문자열을 추출함
< 문법 >
SUBSTR( 컬럼명|표현식, m [,n] ) m : 시작 위치, n : 반환받을 문자열 갯수< 실예 >
SELECT SUBSTR('900303-1234567' , 8 , 1 )
FROM dual;
SELECT last_name, hire_date 입사일, SUBSTR(hire_date,1,2) 입사년도
FROM employees
ORDER BY hire_date;
음수값으로 지정해도 된다.
-- 음수값 시작 위치점
SELECT SUBSTR('900303-1234567' , 13 )
FROM dual;SELECT SUBSTR('900303-1234567' , -2 )
FROM dual;
7) REPLACE 함수 ==> 특정 문자열을 치환
< 문법 >
REPLACE( 컬럼명|표현식, 's1', 's2' ) --> s1 문자를 s2문자열로 치완< 실예 >
SELECT REPLACE('JACK and JUE' , 'J' , 'BL' )
FROM dual;
SELECT REPLACE('JACK and JUE' , 'JA' , 'LO' )
FROM dual;
8) LPAD 함수 ==> 문자열을 오른쪽 정렬 후에 특정 문자를 왼쪽부터 채움
< 문법 >
LPAD( 컬럼명|표현식, n , 'str' ) --> 컬럼을 n만큼 str을 갖고 채워넣어라< 실예 >
SELECT LPAD('MILLER' , 10 , '*' )
FROM dual; --MILLER를 10자리만큼 *로 채워넣어라
9) RPAD 함수 ==> 문자열을 왼쪽 정렬 후에 특정 문자를 오른쪽부터 채움
< 문법 >
RPAD( 컬럼명|표현식, n , 'str' )< 실예 >
SELECT RPAD('MILLER' , 10 , '*' )
FROM dual;
-- 주민번호 1 ~ 8까지 문자열 추출, ******하고 연결
SELECT SUBSTR('900303-1234567',1,8)||'******' 주민번호
FROM dual;
--SUBSTR( 컬럼명|표현식, m [,n] ) m : 시작 위치, n : 반환받을 문자열 갯수SELECT RPAD(SUBSTR('900303-1234567',1,8),14,'*' ) 주민번호
FROM dual;
10) LTRIM 함수 ==> 문자열 처음에서부터 특정문자 삭제 or 공백 삭제
(처음 발견된 것 + 다음에도 있으면 지움, 연속되지 않으면 이후 해당 문자는 못 지움)
< 문법 >
LTRIM( 컬럼명|표현식, ‘str' ) ==> 문자열을 지정하지 않으면 공백 삭제< 실예 >
SELECT LTRIM('MMILLEMERMM', 'M'), RTRIM('MMILLEMERMM', 'M')
FROM dual;
SELECT LTRIM(' MILLER '), LENGTH(LTRIM(' MILLER ')) -- 왼쪽 공백 삭제
FROM dual;
SELECT RTRIM(' MILLER '), LENGTH(RTRIM(' MILLER ')) -- 오른쪽 공백 삭제
FROM dual;
11) TRIM 함수 ==> LTRIM 기능과 RTRIM 기능을 포함한 양쪽을 모두 삭제하려면 TRIM 함수를 사용
< 문법 >
TRIM( LEADING 'str' FROM 컬럼명|표현식 ) ==> 앞에서부터
TRIM( TRAILING 'str' FROM 컬럼명|표현식 ) ==> 뒤에서부터
TRIM( BOTH 'str' FROM 컬럼명|표현식 ) ==> 양쪽에서
-->> 키워드를 생략하는 경우 BOTH가 기본으로 동작된다.< 실예 >
SELECT TRIM( '0' FROM '0001234567000' )
FROM dual;
SELECT TRIM( LEADING '0' FROM '0001234567000' )
FROM dual;
SELECT TRIM( TRAILING '0' FROM '0001234567000' )
FROM dual;
3. 숫자 함수 (단일행 함수)
1) Round 함수 ==> 반올림
< 문법 >
ROUND( 컬럼명|표현식 , [n])< 실예 >
SELECT ROUND( 456.789, 2 ) --반올림하여 소숫점 2번째 자리까지
FROM dual; --456.79
SELECT ROUND( 456.789, -1 ) --정수 1의자리에서 반올림
FROM dual; --460
SELECT ROUND( 456.789 ) -- 기본 값 = 반올림하여 소숫점 제거, 정수 표현
FROM dual; --457
2) TRUNC 함수 ==> 내림 (절삭), truncate
< 문법 >
TRUNC( 컬럼명|표현식 , [n])< 실예 >
SELECT TRUNC( 456.789, 2 ) --반올림하여 소숫점 2번째 자리까지
FROM dual; --456.78
SELECT TRUNC( 456.789, -1 ) --정수 1의자리에서 내림
FROM dual; --460
SELECT TRUNC( 456.789 ) -- 기본 값 = 내림하여 소숫점 제거, 정수 표현
FROM dual; --456
3) MOD 함수 ==> 나누기 연산을 한 후에 몫이 아닌 나머지를 반환
< 문법 >
MOD( 컬럼명|표현식 , n)< 실예 >
SELECT MOD( 10 , 3 ) , MOD( 10 , 0 )
FROM dual;
4) CEIL 함수 ==> 소수점을 가진 실수값을 정수값으로 반환하는 함수, 크거나 같은 최소 정수값을 반환
< 문법 >
CEIL( 컬럼명|표현식 )< 실예 >
SELECT CEIL(10.6), CEIL(-10.6)
FROM dual; -- 11, -10
5) FLOOR 함수 ==> 소수점을 가진 실수값을 정수값으로 반환하는 함수, 주어진 숫자보다 작거나 같은 최대 정수값을 반환
< 문법 >
FLOOR( 컬럼명|표현식 )< 실예 >
SELECT FLOOR(10.6), FLOOR(-10.6)
FROM dual; -- 10, -11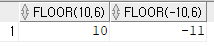
6) SIGN 함수 ==> 지정된 값이 양수인지 음수인지 또는 0인지 판단할 수 있는 함수
양수 => 1, 음수 => -1, 0
< 문법 >
SIGN( 컬럼명|표현식 )< 실예 >
SELECT SIGN( 100 ) , SIGN(-20) , SIGN(0)
FROM dual; -- 1, -1, 0
SELECT employee_id,last_name,salary
FROM employees
WHERE SIGN(salary-15000)=1; -- 월급이 15000보다 많은가. salary - 15000했을때 양의 정수값이 나오는가
4. 날짜 함수 (단일행 함수)
1) SYSDATE 함수 ==> 시스템의 현재 날짜를 반환
< 실예 >
SELECT SYSDATE, SYSTIMESTAMP
FROM dual; --시, 분, 초까지 출력
--시스템 파라미터 이름 찾기
select *
from nls_session_parameters;
YY 타입 / RR타입 ==> YY타입 == 현재 세기 = 21세기 2000년도. 현재(20년)에 88년 출력 => 2088년 출력
==> RR타입 == 가까운 시대에 시스템이 맞춰줌. 50년도 이전에 50년도 이상의 값을 호출하면 이전세기 현재(20년) 88년 => 1988년



----YY / RR 실습-----
create table aa ( a date, b date ); -- aa이름의 테이블, a와 b 날짜 데이터 생성
insert into aa (a, b) -- (record) 행 삽입
values ( to_date('20/09/10', 'RR/MM/DD' ), to_date('20/09/10', 'RR/MM/DD' ) );
insert into aa (a, b)
values ( to_date('95/01/01', 'RR/MM/DD' ), to_date('95/01/01', 'YY/MM/DD' ) ); -- to_date : 날짜가 아닌 데이터, 날짜 데이터로 변경
select a, b
from aa;
select to_char (a, 'RRRR'), to_char(b, 'YYYY')
from aa;
표 3-7 날짜 연산 p.134
| 연산 | 결과 | 설명 |
| 날짜 + 숫자 | 날짜 | 날짜에 일수를 더하여 반환한다. |
| 날짜 - 숫자 | 날짜 | 날짜에 일수를 빼고 반환한다. |
| 날짜 - 날짜 | 날짜 | (일수) 두 날짜의 차이(일수)를 반환한다. |
| 날짜 + 숫자/24 | 날짜 | 날짜에 시간을 더한다. |
SELECT SYSDATE 오늘, SYSDATE+1 내일, SYSDATE-1 어제
FROM dual;
-- 사원의 근무 년수 출력 ('일 수')
SELECT last_name, hire_date, TRUNC((sysdate-hire_date)/365) "년"
FROM employees
ORDER BY 3 desc;
2) MONTH_BETWEEN 함수 ==> 날짜와 날짜 사이의 '개월 수'를 반환하는 함수
< 문법 >
MONTHS_BETWEEN( date1, date2 )< 실예 >
SELECT last_name, hire_date, MONTHS_BETWEEN(sysdate, hire_date) "근무 월수"
FROM employees
ORDER BY 3 desc;
--반올림--
SELECT last_name, hire_date, ROUND(MONTHS_BETWEEN(sysdate, hire_date)/12, 1) ||' 년 근무' as "근무 년차"
FROM employees
ORDER BY 3 desc;
3) ADD_MONTHS 함수 ==> 지정된 날짜에 특정 개월 수를 더하거나 뺀 날짜를 반환
< 문법 >
ADD_MONTHS( date1, n )< 실예 >
SELECT sysdate 현재, ADD_MONTHS(sysdate,1) 다음달,
ADD_MONTHS(sysdate,-1) 이전달
FROM dual;
4) NEXT_DAY 함수 ==> 지정된 날짜 기준, 돌아오는 가장 가까운 요일
< 문법 >
NEXT_DAY( date1, 'string'|n ) --date1는 지정된 날짜를 의미하고 ‘string' 값은 돌아오는 요일< 실예 >
SELECT last_name, hire_date, NEXT_DAY(hire_date, '금'), NEXT_DAY(hire_date, 6)
FROM employees
ORDER BY 3 desc; -- 고용된날 이후 첫 금요일
select next_day(sysdate, '수'), next_day(sysdate, '수요일'), NEXT_DAY(SYSDATE, 4)
from dual; -- 돌아오는 첫 수요일은?
5) LAST_DAY 함수 ==> 해당 달의 마지막 날짜 반환
< 문법 >
LAST_DAY( date1)< 실예 >
SELECT last_name, hire_date, LAST_DAY(hire_date)
FROM employees
ORDER BY 2 desc; -- 입사한 달의 마지막 날짜
select last_day(sysdate)
from dual; --이번달 마지막 날짜
6) ROUND 함수 ==> ROUND 함수를 사용하여 가장 가까운 년도 또는 월로 반올림
< 문법 >
ROUND( date1 , 'YEAR') , ROUND(date1, 'MONTH')< 실예 >
SELECT last_name, hire_date,
ROUND(hire_date,'YEAR'),
ROUND(hire_date,'MONTH')
FROM employees;
7) TRUNC 함수 ==> TRUNC 함수를 사용하여 가장 가까운 년도 또는 월로 절삭, 버림
< 문법 >
TRUNC( date1 , 'YEAR') , TRUNC((date1, 'MONTH')< 실예 >
SELECT last_name, hire_date,
TRUNC(hire_date,'YEAR') "입사 년도",
TRUNC(hire_date,'MONTH') "입사 월"
FROM employees;
4. 변환함수 (단일행 함수) p.142
| 함수 | 설명 | 반환값 |
| TO_NUMBER | 문자 데이터를 숫자 데이터로 변환한다. | 숫자 |
| TO_DATE | 문자 데이터를 날짜 데이터로 변환한다. | 날짜 |
| TO_CHAR | 숫자 데이터를 문자 데이터로 변환하거나 날짜 데이터를 문자 데이터로 변환한다. | 문자 |
>>자동 형변환

--자동 형변환 되는 예제로서 월급(salary)이 17000인 사원 정보를 출력
SELECT last_name, salary
FROM employees
WHERE salary = '17000';
>>명시적 형변환

--명시적 형변환
SELECT last_name, salary
FROM employees
WHERE salary = to_number('17000');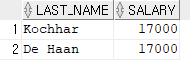
1) to_char함수 ==> 숫자 및 날짜를 문자로 변환
< 문법 >
TO_CHAR( number|date, 'format')< 실예 >
-- 날짜 데이터를 특정 포멧으로 출력 2020년 09월 09일 p.145(날짜 출력 형식)
select sysdate, to_char(sysdate), --20/09/10
to_char(sysdate, 'YYYY'), --2020
to_char(sysdate, 'YY'), --20
to_char(sysdate, 'MM'), --09
to_char(sysdate, 'MON'), --9월
to_char(sysdate, 'DAY'), --목요일
to_char(sysdate, 'DY'), --목
to_char(sysdate, 'DD') --10
from dual;select sysdate, to_char(sysdate), to_char(sysdate, 'YYYY-MM-DD-DAY-DY')
from dual;
--** 'YYYY "년"'
SELECT TO_CHAR(SYSDATE, ' YYYY"년" MM"월" DD"일" ') 날짜
FROM dual;
숫자 데이터를 특정 포멧으로 출력
숫자 출력 형식
| 숫자 형식 | 설명 | 사용예 | 실행 결과 |
| 9 | 한 자리의 숫자 표현 | (111, '999999') | 1111 |
| 0 | 앞 부분을 0으로 표현 | (1111, '099999') | 001111 |
| $ | 달러 기호를 앞에 표현 | (1111, $99999') | $1111 |
| . | 소수점 표시 | (1111, '99999.99') | 1111.00 |
| , | 특정 위치에 , 표시 | (1111, '99,999') | 1,111 |
| B | 공백을 0으로 표현 | (1111, 'B9999.99') | 1111.00 |
| L | 지역 통화(Local currency) | (1111, 'L99999') | ₩1111 |
SELECT last_name, salary,
TO_CHAR(salary, '$999,999') 달러,
TO_CHAR(salary, 'L999,999') 원화
FROM employees;
2) TO_NUMBER 함수 ==> 숫자 형태의 문자열을 숫자로 변환
< 문법 >
TO_NUMBER( str )< 실예 >
SELECT TO_NUMBER('123') + 100
FROM dual;SELECT '123' + 100 --이렇게 자동 형변환이 되긴하는데.. 그래도 쓰일때가 있다. 알아두자.
FROM dual;
3) TO_DATE 함수 ==> 날짜 형태의 문자열을 명시된 날짜 데이터로 변환
< 문법 >
TO_DATE( str , 'format' )< 실예 >
--먼저,
--기본 RR/MM/DD 형식을 다른 형식으로 변경하기 위해서 다음과 같이 ALTER 명령문을 사용하여 NLS_DATE_FORMAT 파라미터값을 변경
ALTER SESSION SET NLS_DATE_FORMAT='YYYY/MM/DD HH24:MI:SS';select to_date('20200909'),
to_date('20200909', 'YYYYMMDD'),
to_date('20200909163230', 'YYYYMMDDHH24MISS')
from dual;
SELECT TO_DATE( '20170802181030' , 'YYYYMMDDHH24MISS' )
FROM dual;
--날짜 정보 관리
--1) 2020년09월10일 16시36분
--2) 202009101636 ==> 이후 응용 / 확장성이 더 높은 형식이다.
오늘 수업은 생각보다는 많이 나가지 않았어요.
강사님께서도 조금 속도가 늦다싶으셨는지 끝나고서 속도가 쫌 루즈하지 않냐고 물어보시더라구요.
조금 더 빠르게 나가셔도 될 것 같습니다. 라고 말씀드렸죠.
내일부터는..... 더 많아지려나;;;; ㅎㅎㅎ
쨋든, 그럼 이만~
'SK 행복성장캠퍼스 > SQL' 카테고리의 다른 글
| 2020-09-10, SQL_3일차 (0) | 2020.09.11 |
|---|---|
| 2020-09-09, SQL_2일차_연습문제 (0) | 2020.09.10 |
| 2020-09-08, SQL_1일차_연습문제 (0) | 2020.09.09 |
| 2020-09-08, SQL_1일차 (0) | 2020.09.09 |
| 2020-09-07, oracle db, sql developer 설치하기 (0) | 2020.09.08 |




댓글